
Formatowanie łańcuchów znaków w Pythonie
W języku Python istnieją cztery podstawowe sposoby na formatowanie łańcuchów znaków (od wersji 3.6 wzwyż). W niniejszym wpisie chciałbym je pokrótce omówić, przedstawić ich wady i zalety, a w podsumowaniu udzielić wskazówek, którą z metod wybierać i w jakiej sytuacji.
Zanim przejdę do szczegółowego omówienia metod przyjrzyjmy się następującej sytuacji. Załóżmy że mamy następujące zmienne:
>>> messages_count = 12
>>> user_name = 'Peter'i naszym zadaniem jest wygenerować poniższy łańcuch znaków w formie komunikatu:
'Hello Peter, you have 12 unread message(s)'Zrealizujmy to zadanie wszystkimi czterema metodami, tak aby te metody lepiej poznać.
1. Formatowanie łańcuchów “starą” metodą
Łańcuchy znaków w Pythonie są reprezentowane przez obiekty clasy str. Są niezmienne (immutable) i tworzymy je poprzez umieszczenie danego tekstu w cudzysłowiach:
- pojedynczych: ‘this is a string’
- podwójnych: “this is a string”
- potrójnych: ‘'’this is a string’’’ lub “"”this is a string”””
Potrójne cudzysłowy pozwalają także na tworzenie łańcuchów wielolinijkowych.
Na łańcuchach znaków w Pythonie możemy wykonywać specjalne działanie z wykorzystaniem operatora %. Dzięki temu operatorowi możemy w łatwy sposób formatować wynikową zawartość. To działanie jest bardzo podobne do działania funkcji printf z języka C. Zobaczmy na przykładzie:
>>> 'Hello %s' % user_name
'Hello Peter'Rezultatem wykonanie tego wyrażenia jest łańcuch znaków, w którym specjalnea sekwencja formatująca %s została zastąpiona wartością znajdującą się w zmiennej user_name.
Do dyspozycji mamy wiele specyfikatorów formatu, np. dla liczb całkowitych jest to %d, a dla zmiennoprzecinkowych %f. Po szczegóły dotyczące dostępnych specyfikatorów i ich użycia odsyłam do dokumentacji języka Python.
W sytuacji, gdy potrzebujemy zastosować więc niż jeden specyfikator formatu, musimy zastosować nieco inną składnię:
>>> 'Hello %s, you have %d unread messages(s)' % (user_name, messages_count)
'Hello Peter, you have 12 unread message(s)'Możemy też tworzyć nazwane specyfikatory formatu i jawnie przekazywać pożądane wartości za pomocą słownika:
>>> 'Hello %(name)s, you have %(count)d unread messages(s)' % {'name': user_name, 'count': messages_count}
'Hello Peter, you have 12 unread message(s)'To ostatnie rozwiązanie jest bardziej elastyczne, gdyż umożliwia łatwiejsze rozbudowanie takiego łańucha w przyszłości, a także nie wymusza na nas dbania o prawidłową kolejność przekazywanych zmiennych.
2. Formatowanie łańcuchów “nową” metodą
Wraz z wersją Pythona z linii 3 wprowadzono “nową” metodę do formatowania łańcuchów znaków. Ta “nowa” metoda pozwala nam zrezygnować z używania operatora %, przez co składnia naszego kodu staje się bardziej przejrzysta i czytelniejsza. Do klasy str dodano dodatkową metodę format(), dzięki wywołaniu której możemy wpływać na wynikową postać naszego sformatowanego łancucha. Wspomnieć tutaj należy, że metoda ta została później backportowana do Pythona 2 aby i w tej wersji języka można było z niej korzystać. Zobaczmy na prostym przykładzie jak wygląda formatowanie:
>>> 'Hello {}'.format(user_name)
'Hello Peter'Tworzymy w nim obiekt klasy str i wywołujemy jego metodę format(), której zadaniem jest w tym przypadku, zastąpienie sekwencji {} wartością argumentu metody format. Wracając do naszego zadania kod mógłby wyglądać następująco :
>>> 'Hello {}, you have {} unread messages(s)'.format(user_name, messages_count)
'Hello Peter, you have 12 unread message(s)'Kolejne wystąpienia sekwencji {}, są odpowiednio zastępowane wartościami przekazywanymi do metody format. Możemy skorzystać, tak jak w przypadku starej metody, z podstawiania zmiennych, aby nie musieć martwić się o kolejność argumentów. W łatwy też sposób możemy zamieniać kolejność wyswietlanych elementów, bez zmiany kolejności argumentów w metodzie format():
>>> 'Hello {name}, you have {count} unread messages(s)'.format(count=messages_count, name=user_name)
'Hello Peter, you have 12 unread message(s)'W przypadku tej metody także nie mogło zabraknąć możliwości określania sposobu wyświetlania wartości w sekwencji formatującej. Aby np wyświetlić liczbę całkowita jako jej reprezentację szesnastkową możemy napisac:
>>> '0x{count:X}'.format(count=messages_count)
'0xC'Składnia sekwencji formatującej jest dużo bardziej rozbudowana i daje większe możliwości niż w starej metodzie ale jednocześnie jest łatwa do używania w prostszych przypadkach. W celu zgłębienia szczegółów zachęcam do zapoznania się z dokumentacją.
Pisząc programy w Pythonie 3 oficjalna dokumentacja zaleca korzystać z nowszych metod formatowania łańcuchów kosztem starej metody. Stara metoda nadal może być wykorzystywana, nadal jest (i będzie) wspierana w kolejnych wydaniach Pythona.
3. Interpolacja łańcuchów
Interpolacja łańcuchów znaków (f-strings) została wprowadzona po raz pierwszy w Pythonie wraz z wersją 3.6. Pisząc krótko, ten nowy sposób pozwala nam osadzać wyrażenia Pythona wewnątrz stałych łańcuchów znaków. Zobaczmy jak wygląda najprostszy przykład:
>>> f'Hello, {user_name}!!!'
'Hello, Peter!!!'Jak widzimy nowością jest literka f przed łańcuchem znaków (stąd nazwa f-strings). Jest to bardzo elastyczny sposób, choć niosący pewne ograniczenia. Z racji, że można w łańcuchah znaków osadzać wyrażenia, możemy wykonywać operacje arytmetyczne wewnątrz:
>>> f'{messages_count+3} or {10+5}'
'15 or 15'Oprócz wyrażeń możemy także bezpośrednio wywoływać funkcje/metody:
>>> def to_uppercase(s):
... return s.upper()
>>> name = 'Peter Wright'
>>> f'Hello, {to_uppercase(name)}!'
'Hello, PETER WRIGHT!'
>>> f'Hello, {name.lower()}!'
'Hello, peter wright!'Także możemy używać obiektów utworzonych z klas. Weźmy dla przykładu nastapującą prostą klase:
class Person:
def __init__(self, first_name, last_name, age):
self.first_name = first_name
self.last_name = last_name
self.age = age
def __str__(self):
return f'{self.first_name} {self.last_name} is {self.age}.'
def __repr__(self):
return f'{self.first_name}-{self.last_name}-{self.age}'I na jej podstawie możemy napisać:
>>> person = Peron('Peter', 'Wright', 34)
>>> f'{person}
'Peter Wright is 34.'Magiczne metody __str__() i __repr__() odpowiadają za reprezentację łańcuchową obiektu, więc przynajmniej jedną powinniśmy umieścić w definicji klasy. Jeśli musiałbyś wybierać którą z tych dwóch metod implementować, to wybierz __repr()__, gdyż może ona być używana w zastępstwi __str__().
Łańcuch znaków zwracany przez metodę __str__() jest nieformalną (informacyjną) reprezentacją znakową obiektu i powinien być czytelny dla nas. Łańcuch znaków zwracany przez metodę __repr__() jest to formalna (oficjalna) reprezentacja napisowa obiektu i powinna być jednoznaczna, a otrzymany łańcuch znaków powinien być poprawnym wyrażeniem w Pythonie. W metodzie interpolacji łańcuchów domyślnie używana jest metoda __str__() (podobnie ma to miejsce w przypadku format()), aby uzywać metody __repr__() przy formatowaniu musimy jawnie wyspecyfikować flagę konwersji !r:
>>> f'{person}
'Peter Wright is 34.'
>>> f'{person!r}
'Peter-Wright-34.'W tym miejscu, każdy z Was powinien już umieć napisać kod realizujący nasze zadanie za pomocą f-stringów. Dla formalności zoabczmy jak to zapisać:
>>> f'Hello {user_name}, you have {messages_count} unread messages(s)'
'Hello Peter, you have 12 unread message(s)'Dla osób czujących potrzębę zanurkowania głębiej podaję link do szczegółów specyfikacji.
4. Szablony
W języku Python isntnieje jeszcze jedna metoda na formatowanie łańcuchów znaków - są to szablony. Jest to prostsza i mniej elastyczna metoda, jednak w pewnych przypadkach może być bardzo pomocna. Popatrzmy na prosty fragment kodu:
>>> from string import Template
>>> template = Template('Hello, $name!')
>>> template.substitue(name=user_name)
'Hello, Peter!'Na początku musimy zaimportować klasę Template z wbudowanego w Pythona modułu string, utworzyć obiekt tej klasy przekazując łańcuch znaków, a następnie dokonać podstawienia wartości. W tej metodzie, w odróżnieniu od pozostałych nie wsytępują specyfikatory formatów, dlatego musimy wcześniej sami zatroszczyć się o odpowiednie konwersje i przekazać przygotowane już wartości w zmiennych do podstawienia.
Rodzi się zatem pytanie, kiedy używać tej metody w programach. W mojej opinii, tam gdzie przetwarzamy łańcuchy znaków otrzymane od użytkowników programu. Z racji ograniczonej funkcjonalności wykorzystywanie szablonów w tym wypadku będzie najbezpieczniejszym wyborem. Jak się okazuje bardziej rozbudowane metody formatowania mogą w takiej sytuacji stanowić luki bezpieczeństwa w naszym programie. Złośliwy użytkownik może tak przygotować łańcuch znaków do formatowania aby wykraść nam jakieś wrażliwe dane. Zobaczmy jakby to mogło wyglądać:
>>> # To jest nasze tajne hasło
>>> SECRET_PASSWORD = 'my-secret-password'
>>> class Message:
>>> def __init__(self):
>>> pass
>>> # złosliwy użytkownik np. poprzez pole formularza przekazuje nam nastepujący tekst
>>> user_input = '{message.__init__.__globals__[SECRET_PASSWORD]}'
>>> msg = Message()
>>> user_input.format(message=msg)
'my-secret-password'Ups.. Potencjalny atakujący może dostać sie do słownika __globals__ poprzez ciąg formatujący. Powtórzmy to teraz dla szablonów:
>>> user_input = '${message.__init__.__globals__[SECRET_PASSWORD]}'
>>> Template(user_input).substitute(messages=msg)
ValueError: Invalid placeholder in string: line 1, col 1No dobrze, to której metody mam używać?
Poznaliśmy już dostępne metody formatowania łańcuchów i zasady ich działania w Pythonie to teraz przyszła pora na podsumowanie. Wobec mnogości dostępnych metod mogą pojawić się wątpliwości co do tego, której metody używać. O części zasad już wspomniałem wyżej, ale chciałbym jeszcze pokazać to w formie jednej praktycznej porady:
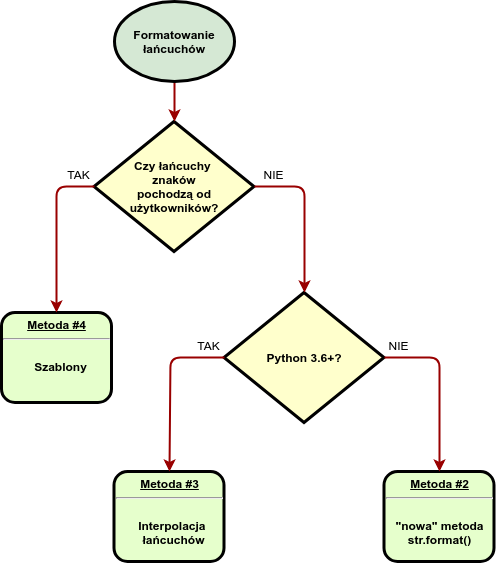
Jeśli formatowane łańcuchy pochodzą od użytkowników używamy szablonów (#4) ze względów bezpieczeństwa. W przeciwnym wypadku używamy Interpolacji łańcuchów (f-strings) (#3) jeśli piszemy kod dla Pythona 3.6+, albo “nowej” metody (#2) dla starszych wersji języka.
Na zakończenie przyjrzyjmy się jeszcze wydajności prezentowanych metod. Do zbadania i prównania wydajności napiszemy prosty program, który zmierzy czasy formatowania łańcuchów znaków dla każdej z meteod. Skorzystamy tutaj z modułu timeit i przy jego pomocy będziemy uruchamiać metody określoną liczbę razy.
from timeit import repeat
from string import Template
number = 50000
def method_1():
for i in range(number):
"Metohd #1 - %s" % i
def method_2():
for i in range(number):
"Method #2 - {}".format(i)
def method_3():
for i in range(number):
f"Method #3 - {i}"
def method_4():
template = Template("Method #4 - $value")
for i in range(number):
template.substitute(value=i)
time_1 = repeat(stmt=method_1, repeat=5, number=100)
time_2 = repeat(stmt=method_2, repeat=5, number=100)
time_3 = repeat(stmt=method_3, repeat=5, number=100)
time_4 = repeat(stmt=method_4, repeat=5, number=100)
print("Method #1: {} secs".format(min(time_1)))
print("Method #2: {} secs".format(min(time_2)))
print("Method #3: {} secs".format(min(time_3)))
print("Method #4: {} secs".format(min(time_4)))Wykonaliśmy dla każdej metody 5 serii po 5 milionów podstawień i otrzymaliśmy następujące wyniki:
Method #1: 0.8946281759999692 secs
Method #2: 1.281472788999963 secs
Method #3: 0.7678051210004924 secs
Method #4: 16.648385618999782 secsSame wartości czasowe dla poszczególnych metod nie są o tyle istotne, co różnice między nimi. Widać wyraźnie, że pod względem wydajnościowym najlepiej wypada metoda #3 interpolacji łańcuchów, a metoda z wykorzystaniem szablonów jest zdecydowanie najmniej wydajna szybkościowo. Metoda .format() jest nieco mniej wydajna w porównaniu do operatora ‘’%’’.




Zostaw komentarz